LatencyOWL – Netzwerk-Monitoring für Windows
Version 1.0.0
LatencyOWL ist ein selbst gehostetes Netzwerk-Monitoring-Tool, das speziell für den Einsatz unter Windows entwickelt wurde. Es überwacht die Erreichbarkeit und Latenz beliebiger Netzwerkziele in Echtzeit und stellt die Ergebnisse in einem modernen, browserbasierten Dashboard dar.
Das Projekt entstand aus dem Bedarf heraus, eine leichtgewichtige Alternative zu etablierten Monitoring-Lösungen wie SmokePing oder PRTG zu schaffen, die ohne komplexe Infrastruktur auskommt und sich in wenigen Minuten einrichten lässt – ohne Linux-Server, ohne Docker, ohne externe Datenbank.
Funktionen im Überblick
Multi-Protokoll-Monitoring
Ping (ICMP), HTTP/HTTPS, DNS, TCP, SNMP und SSL-Zertifikatsprüfung in einer Anwendung.
Latenz-Graphen & Heatmap
SmokePing-inspirierte Graphen mit Percentile-Overlays, Heatmap und Uptime-Kalender.
Alerting mit Eskalation
Benachrichtigungen per Webhook, E-Mail, ntfy oder Microsoft Graph – mit konfigurierbarer Eskalation und Anomalie-Erkennung.
Geo-Map & Remote Agents
Verteiltes Monitoring von mehreren Standorten mit automatischer IP-Geolocation auf einer interaktiven Karte.
Throughput-Tests
Eingebauter Bandbreitenmesser (vergleichbar mit iperf3) für TCP- und UDP-Messungen zwischen Systemen.
SLA-Reports & PDF-Export
Automatische Verfügbarkeitsberichte mit PDF-Export und optionalem E-Mail-Versand.
Dashboard & Kiosk-Modus
Web-Dashboard mit Dark/Light-Theme, Deutsch/Englisch, Tastenkürzel und Kiosk-Modus.
Windows-Dienst
Läuft als Windows-Dienst im Hintergrund – ohne Datenbank-Server, ohne Docker, ohne Linux.
Monitoring-Protokolle und Messmethoden
Im Kern führt LatencyOWL in konfigurierbaren Intervallen automatisierte Tests gegen beliebig viele Ziele durch. Dabei werden nicht nur klassische ICMP-Pings unterstützt, sondern auch HTTP- und HTTPS-Anfragen mit Prüfung des Statuscodes und optionaler Inhaltsvalidierung, TCP-Verbindungstests gegen bestimmte Ports, DNS-Namensauflösungen über frei wählbare DNS-Server, SNMP-Abfragen sowie SSL-Zertifikatsprüfungen mit Anzeige der verbleibenden Tage bis zum Ablauf.
Pro Messzyklus werden standardmäßig 20 Pings versendet, sodass nicht nur ein einzelner Wert, sondern eine statistische Verteilung pro Messpunkt entsteht. Daraus berechnet LatencyOWL den Median, Minimum, Maximum, Jitter sowie die Percentile P50, P90, P95 und P99 – und natürlich den prozentualen Paketverlust.
Screenshots
Detail-Ansicht mit Latenz-Graph, Traceroute und MTU-Test
Visualisierung und Dashboard
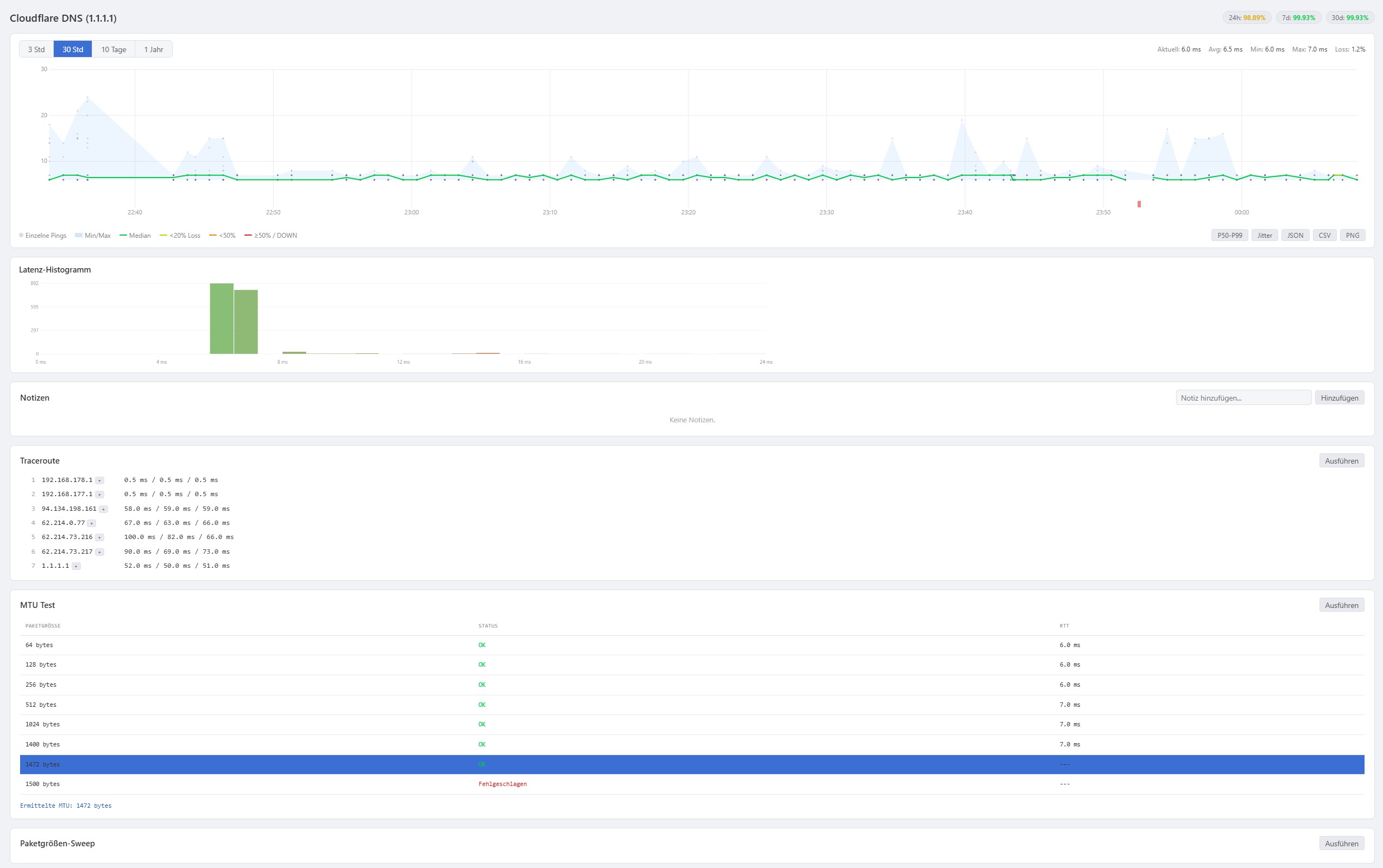
Das Herzstück der Benutzeroberfläche ist der SmokePing-inspirierte Latenzgraph, der die Median-RTT als farbcodierte Linie über die Zeit darstellt. Die Farbe der Linie signalisiert den aktuellen Zustand: Grün bedeutet kein Paketverlust, Gelb zeigt leichten Loss an, Orange steht für erhöhten Verlust und Rot markiert schwerwiegende Ausfälle. Komplettausfälle werden als rote Balken am unteren Rand des Graphs hervorgehoben. Wartungsfenster erscheinen als halbtransparente graue Flächen, damit klar ersichtlich ist, welche Ausfälle geplant waren.
Per Mausklick lassen sich Percentile-Overlays und Jitter-Darstellungen ein- und ausblenden. Ein Latenz-Histogramm zeigt die RTT-Verteilung als Balkendiagramm, und per Zoom-Funktion kann jeder Zeitbereich von drei Stunden bis zu einem Jahr stufenlos untersucht werden.
Heatmap
Latenz oder Paketverlust als farbcodierte Matrix – Stunden auf der X-Achse, Tage auf der Y-Achse. So werden zeitliche Muster wie nächtliche Störungen oder Lastspitzen sofort sichtbar.
Uptime-Kalender
Verfügbarkeit der letzten 365 Tage im Stil der GitHub-Contribution-Map. Jede Zelle steht für einen Tag – von Grün (über 99,9 % Uptime) bis Rot (unter 90 %).
Geo-Map
Alle überwachten Ziele auf einer interaktiven Weltkarte (Leaflet/OpenStreetMap). Positionen werden automatisch per IP-Geolocation ermittelt, der Status durch farbige Punkte signalisiert.
Gruppen-Dashboard
Targets nach frei definierbaren Gruppen zusammengefasst mit Mini-Graphen nebeneinander – ideal für den Überblick über alle DNS-Server, Standort-Gateways oder Kundenanbindungen.
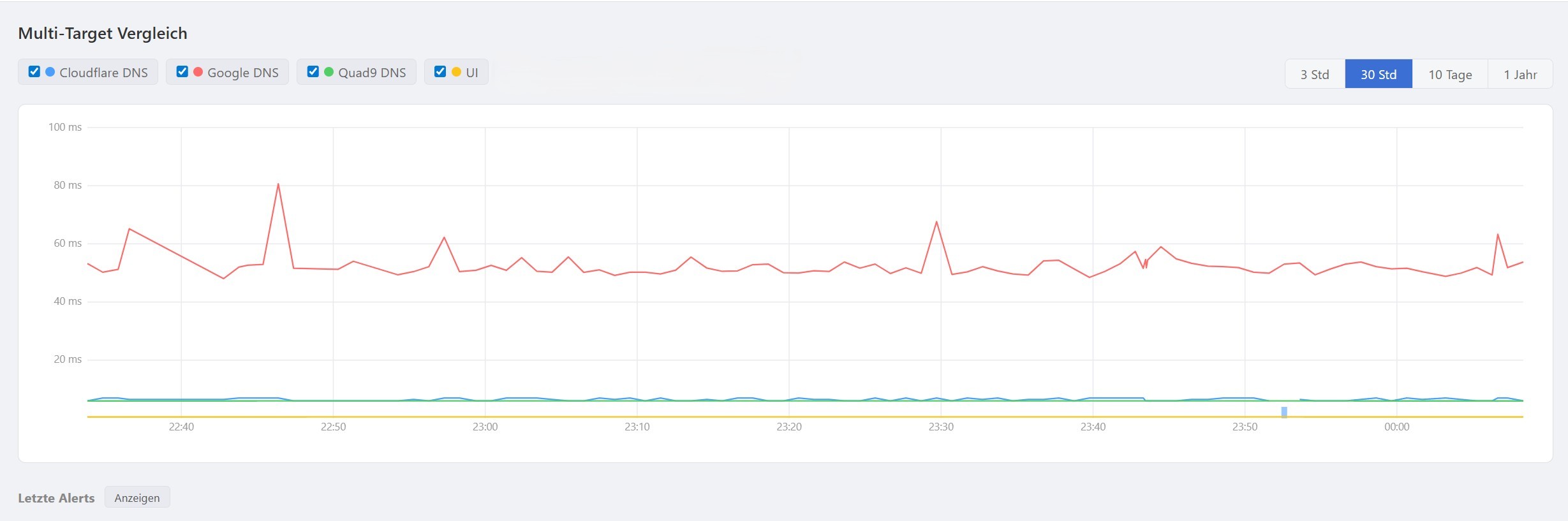
Vergleichsmodus
Mehrere Targets übereinanderlegen, um beispielsweise die Latenz verschiedener DNS-Server oder Standorte direkt gegenüberzustellen.
Incident-Timeline
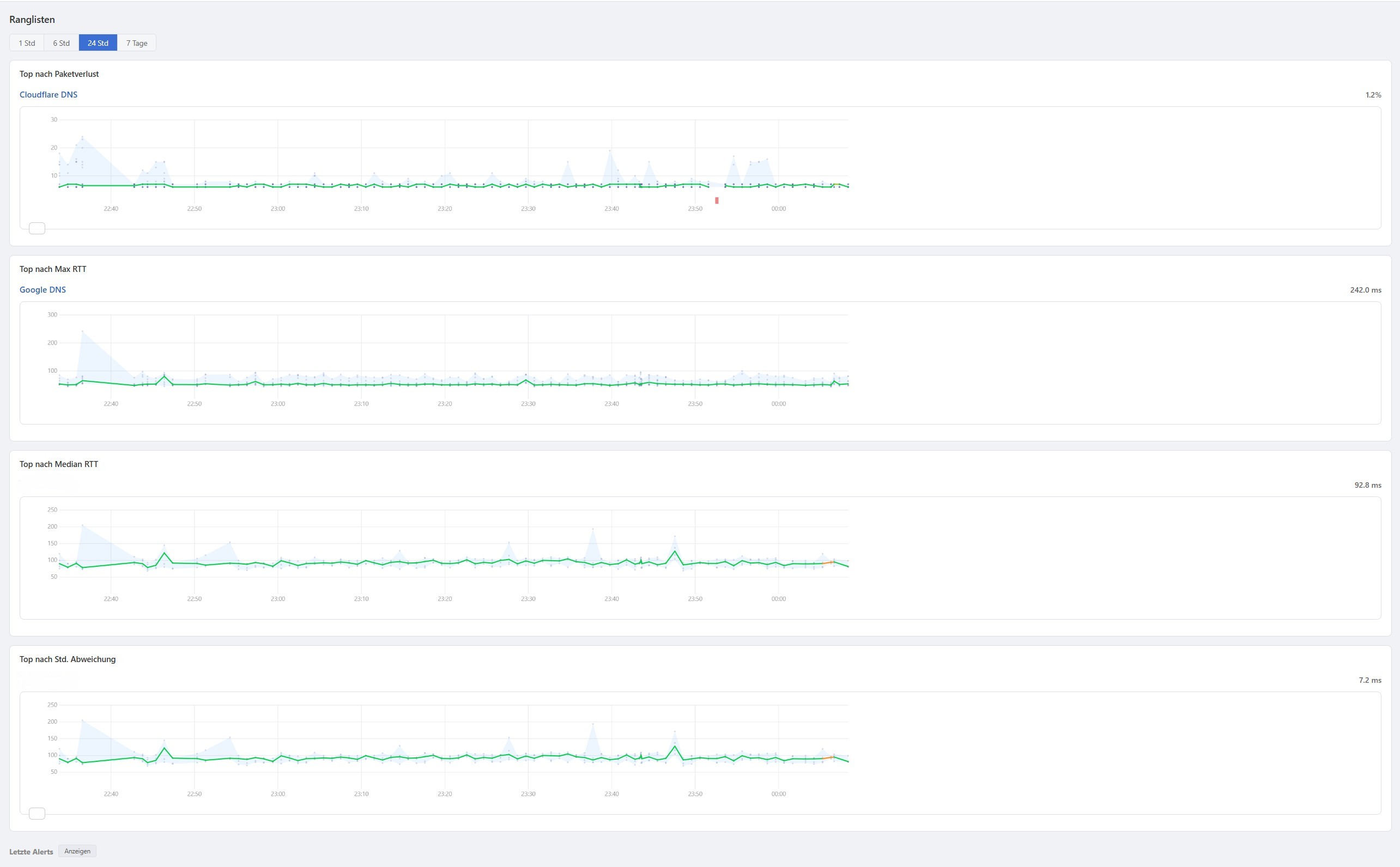
Alle Ausfälle chronologisch aufgelistet, dazu Ranglisten aller Targets nach Latenz, Paketverlust oder Verfügbarkeit.
Alerting und Benachrichtigungen
LatencyOWL verfügt über ein flexibles Alerting-System mit schwellenwertbasierten Regeln. Für jedes Target oder global für alle Ziele gleichzeitig können Bedingungen wie “Median-RTT größer als 100 ms” oder “Paketverlust über 10 Prozent” definiert werden. Wird eine Regel verletzt, löst das System einen Alert aus und versendet Benachrichtigungen über einen oder mehrere Kanäle:
- Webhooks für die Integration in Slack, Microsoft Teams oder beliebige andere Systeme
- Push-Benachrichtigungen über ntfy.sh für mobile Endgeräte
- E-Mails über SMTP
- Microsoft Graph API für Organisationen mit Azure Active Directory
Alerts können bestätigt (acknowledged) werden, um wiederholte Benachrichtigungen zu unterdrücken. Eskalationsstufen aktivieren automatisch den nächsten Benachrichtigungskanal, wenn ein Alert nach einer definierten Zeitspanne nicht bestätigt wurde. Zusätzlich bietet das Frontend einen Sound-Alarm, der bei neuen Alerts einen akustischen Hinweis im Browser abspielt.
Ergänzend zum regelbasierten Alerting verfügt LatencyOWL über eine statistische Anomalie-Erkennung, die auf Basis der Standardabweichung von historischen Messwerten ungewöhnliche Latenzspitzen automatisch identifiziert. Die Empfindlichkeit lässt sich über einen Sensitivitätsfaktor anpassen.
Wartungsfenster
Geplante Wartungsarbeiten können als Wartungsfenster angelegt werden, während derer keine Alerts für die betroffenen Targets ausgelöst werden. Die Messungen selbst laufen weiter, sodass die tatsächliche Erreichbarkeit auch während einer Wartung dokumentiert wird – aber ohne dass das Monitoring-Team mit erwarteten Alarmen überflutet wird.
Der Wartungsplan-Kalender gibt einen Überblick über alle geplanten und vergangenen Wartungsfenster. Einzelne Targets können individuell deaktiviert werden, ohne dass Konfiguration oder historische Daten verloren gehen.
SLA-Reports
Für jedes überwachte Ziel können SLA-Reports über frei wählbare Zeiträume von 7 Tagen bis zu einem Jahr generiert werden. Diese Berichte enthalten die Verfügbarkeit in Prozent, durchschnittliche, minimale und maximale Latenz, mittleren Paketverlust, Anzahl der Statuswechsel (Flaps) sowie die Gesamtzahl der durchgeführten Messungen.
Die Reports können direkt als PDF exportiert werden und eignen sich als Nachweis gegenüber Kunden oder Dienstleistern. Optional lassen sich automatische Reports in konfigurierbaren Intervallen per E-Mail versenden.
Throughput-Tests und Bandbreitenmessung
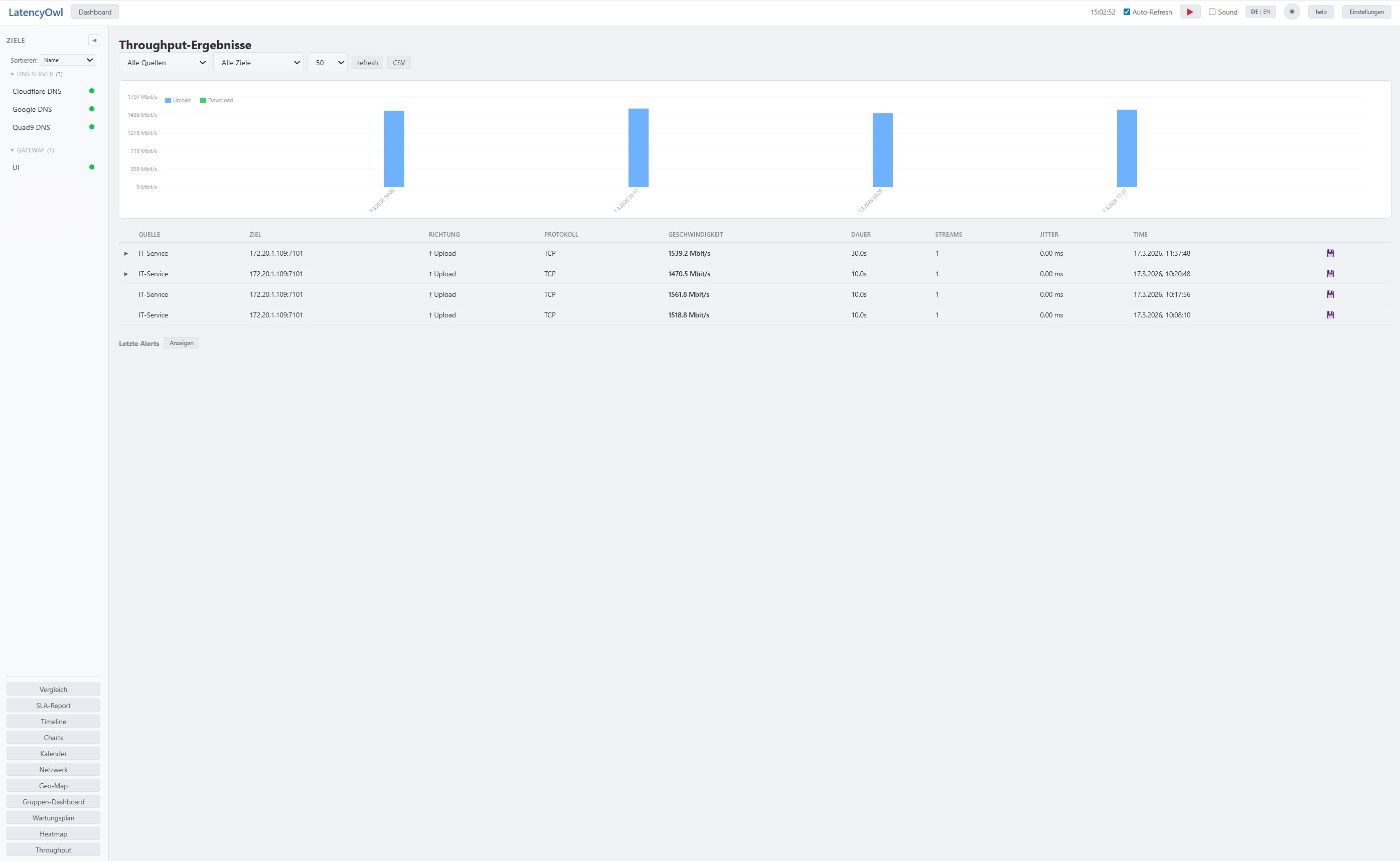
Neben der Latenz- und Verfügbarkeitsüberwachung bringt LatencyOWL einen vollständigen Bandbreitenmesser mit, der funktional mit iperf3 vergleichbar ist, aber ausschließlich in Python implementiert wurde und keine externen Abhängigkeiten benötigt.
Mit dem Throughput-Modul lassen sich TCP- und UDP-basierte Bandbreitentests zwischen beliebigen Rechnern durchführen – inklusive Upload, Download und bidirektionalem Modus, parallelen Streams, Bandbreitenlimitierung sowie UDP-spezifischem Jitter- und Paketverlust-Tracking. Die Ergebnisse werden im Dashboard als Balkendiagramm und Tabelle dargestellt und können nach Quelle, Ziel und Zeitraum gefiltert werden.
Das Throughput-Tool kann als eigenständige EXE-Datei kompiliert werden, die ohne Python-Installation auf dem Zielsystem läuft und Messergebnisse per HTTP an den zentralen LatencyOWL-Server zurückmeldet.
Server starten:
LatencyOWLTP.exe -sClient mit Reporting:
LatencyOWLTP.exe -c 192.168.178.30 --report http://<server>:7100Remote Agents und verteiltes Monitoring
Für verteiltes Monitoring an mehreren Standorten stellt LatencyOWL ein Remote-Agent-Konzept bereit. Ein Agent ist ein kompaktes Programm, das auf einem entfernten Rechner läuft, sich beim zentralen LatencyOWL-Server registriert und regelmäßig Heartbeats sendet. Der Server kann dem Agent Messaufträge zuweisen, die dieser vor Ort ausführt – darunter Ping-, HTTP-, TCP- und DNS-Tests sowie Throughput-Messungen.
Dadurch lässt sich die Erreichbarkeit eines Ziels von verschiedenen Standorten aus gleichzeitig überprüfen. Der Agent kommt ohne externe Python-Pakete aus und kann als eigenständige EXE-Datei verteilt werden.
Agent starten:
LatencyOWLAgent.exe http://<server>:7100 --name "Standort Berlin"Diagnose-Werkzeuge
Direkt aus dem Web-Interface heraus stehen mehrere Diagnose-Tools zur Verfügung:
- Traceroute – alle Hops zum Ziel mit IP und Latenz, einzelne Hops per Klick als neues Target übernehmbar
- MTU-Test – maximale Paketgröße ermitteln durch Don't-Fragment-Pakete in verschiedenen Größen
- Paketgrößen-Sweep – Latenz für 32 bis 1.472 Bytes messen und größenabhängige Engpässe visualisieren
- Netzwerk-Scan – Subnetz in CIDR-Notation durchsuchen, erreichbare Hosts direkt als Targets übernehmen
Statuspage & API
LatencyOWL kann eine öffentliche Statusseite bereitstellen, die den aktuellen Zustand aller überwachten Dienste ohne Authentifizierung anzeigt – mit aktuellem Status, Latenz und Uptime der letzten 24 Stunden, 7 Tage und 30 Tage.
Sämtliche Daten stehen über eine dokumentierte REST-API zur Verfügung: aktueller Status, historische Messdaten, SLA-Berichte, Alert-Logs und Konfigurationsänderungen.
Prometheus-kompatible Metriken ermöglichen die nahtlose Integration in bestehende Monitoring-Stacks mit Grafana oder ähnlichen Tools.
Technologie und Deployment
Das Backend basiert auf Python 3 mit Flask als Web-Framework. Als Datenbank kommt SQLite im WAL-Modus zum Einsatz, wodurch kein externer Datenbankserver benötigt wird und die gesamte Installation aus einer einzigen Anwendung plus einer Datenbankdatei besteht. Das Frontend nutzt Vanilla JavaScript ohne Framework-Abhängigkeiten, rendert Graphen direkt auf dem HTML-Canvas und bindet Leaflet für die Kartenansicht ein.
Die Oberfläche unterstützt ein Dark- und Light-Theme, das per Klick umgeschaltet werden kann, sowie eine vollständige Zweisprachigkeit in Deutsch und Englisch mit Live-Umschaltung im Interface. Tastenkürzel ermöglichen eine schnelle Navigation ohne Maus.
Schnellstart
- 1ZIP-Archiv entpacken (z.B. nach C:\LatencyOWL\)
- 2install.bat ausführen (Doppelklick)
- 3start.bat ausführen (Doppelklick)
- 4Im Browser öffnen: http://localhost:7100
Voraussetzungen
- Windows 10/11 oder Windows Server 2016+
- Python 3.10 oder neuer (empfohlen: Python 3.13)
- Für ICMP-Ping ggf. Administrator-Rechte
- Für Geo-Map: Internetzugang (OpenStreetMap)
Warum LatencyOWL?
Netzwerk-Monitoring muss nicht kompliziert sein. Viele bestehende Tools sind entweder zu komplex in der Einrichtung, erfordern Linux-Kenntnisse oder setzen teure Lizenzen voraus. LatencyOWL wurde speziell für Windows-Umgebungen entwickelt – mit dem Ziel, innerhalb von Minuten einsatzbereit zu sein.
Als IT-Dienstleister in Berlin Spandau setzen wir LatencyOWL selbst bei unseren Kunden ein, um Netzwerkprobleme frühzeitig zu erkennen. Ob Paketverluste bei VoIP-Telefonie, langsame VPN-Verbindungen oder instabile Internetleitungen – LatencyOWL liefert die Daten, die für eine schnelle Diagnose nötig sind.
LatencyOWL entstand aus der täglichen Arbeit als IT-Dienstleister. Statt auf überladene Enterprise-Lösungen zurückzugreifen, wollten wir ein Tool, das genau das tut, was kleine und mittelständische Unternehmen brauchen: Netzwerkziele überwachen, bei Problemen alarmieren und verständliche Auswertungen liefern – ohne wochenlange Einarbeitung.
Jetzt kostenlos herunterladen
LatencyOWL ist kostenlos und sofort einsatzbereit. Einfach entpacken, installieren, starten. Keine Registrierung, keine Lizenzschlüssel, keine versteckten Kosten.
LatencyOWL 1.0.0 herunterladenFragen oder Feedback? support@mt-computerservice.de